



Plus de deux ans après le lancement de ChatGPT d’OpenAI, qui a catalysé une vague d’intérêt pour l’intelligence artificielle générative (IA), les implications à long terme de cette technologie restent très incertaines. Le rythme de l’innovation est rapide, les cadres réglementaires sont encore en évolution et la valeur économique finale de nombreux cas d’utilisation de l’IA doit encore être prouvée. Toutefois, dans ce contexte d’incertitude, les stratégies des géants de la technologie commencent à prendre forme : certains investissent massivement dans la construction de leurs propres modèles, comme Alphabet et Meta, tandis que d’autres adoptent une approche plus agnostique, comme Microsoft et Amazon.
Dans un paysage où les gains de performance des grands modèles de langage (LLM) peuvent être rapidement érodés, la capacité à étendre la distribution à travers des plateformes d’entreprise et grand-public solidement établies s’avérera probablement plus déterminante que la seule différenciation technique. Dans cette lettre d’information, nous examinons la manière dont deux sociétés détenues par Seilern, Microsoft et Alphabet, abordent ce défi. Bien que leurs stratégies puissent différer dans leur mise en œuvre, toutes deux ont reconnu la nécessité d’investissements initiaux importants pour débloquer de nouveaux flux de revenus et renforcer leurs positions concurrentielles, ancrées dans leurs rôles d’hyperscalers du cloud et dans le puissant levier que leur confère cette capacite de distribution.
L’approche agnostique de Microsoft
La stratégie de Microsoft en matière d’IA générative consiste à se concentrer sur la distribution par le biais d’une approche agnostique aux modèles LLM. Contrairement à ses concurrents qui privilégient le développement de modèles de pointe, Microsoft a stratégiquement mis l’accent sur le déploiement en aval, estimant que les LLM sont sur la voie de la banalisation. Bien qu’une grande partie des revenus actuels de Microsoft liés à l’IA, estimés à 13 milliards de dollars en termes annualisés, proviennent des dépenses d’entrainement desmodèles d’OpenAI (« couche calcul » dans la figure ci-dessous) hébergées sur Azure, Microsoft oriente de plus en plus ses investissements dans l’infrastructure et la génération de revenus vers les dépenses d’inférence (« couche application » dans la figure ci-dessous), qui offrent des opportunités de monétisation plus immédiates et, selon l’entreprise, un plus grand potentiel à long terme.
Figure 1 : Exemple de chaîne d’approvisionnement du modèle du grand langage (LLM)1
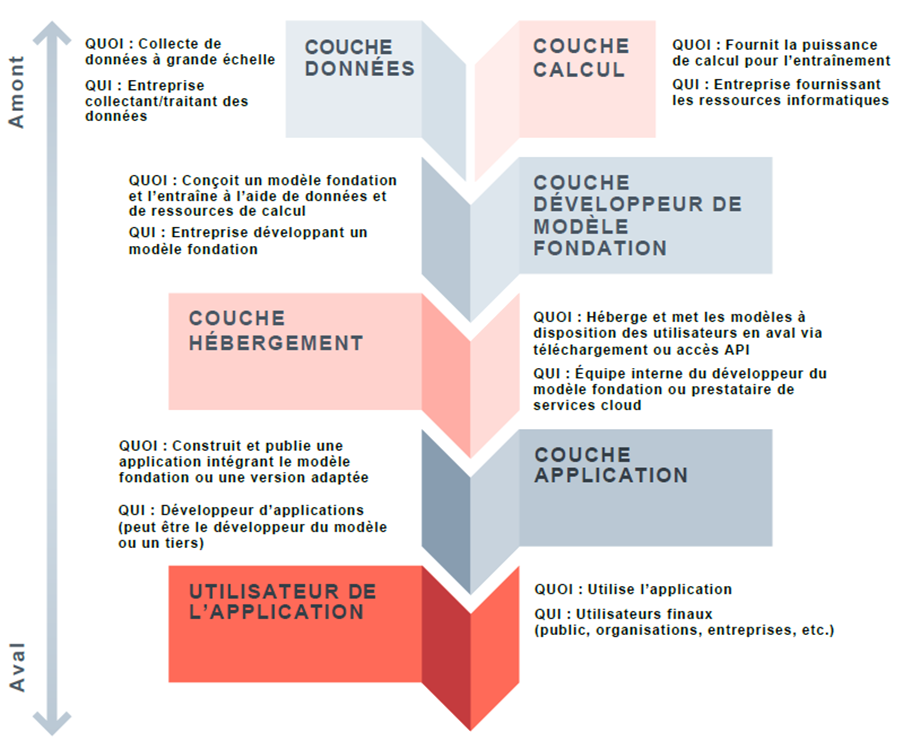
Source : Ada Lovelace Institute L’Institut Ada Lovelace
Un exemple en est la Azure AI Foundry, qui offre aux entreprises clientes un accès à plus de 10 000 modèles, avec un accès exclusif aux modèles d’OpenAI, ainsi qu’à de nombreux autres modèles tels que les modèles open-source de Meta et DeepSeek et, plus récemment, les offres de xAI. L’objectif de la Foundry est de fournir une plateforme unifiée permettant aux développeurs d’utiliser le modèle qui leur convient le mieux et de tester et déployer directement des modèles d’IA. L’objectif final est de stimuler la demande en calcul d’inférence pour le réseau Azure en rendant facile et attrayante l’utilisation d’une gamme variée de modèles d’IA sur leur plateforme. Cette approche agnostique garantit que Microsoft reste un acteur central, quels que soient les modèles d’IA spécifiques qui gagnent en importance.
L’évolution du partenariat de Microsoft avec OpenAI, qui a débuté en 2019, fournit des indications clés sur son orientation stratégique. Notamment, Microsoft est resté absent de l’ambitieux « Projet Stargate » d’OpenAI, qui vise à investir 500 milliards de dollars dans l’infrastructure de calcul au cours des quatre prochaines années. Bien que Microsoft conserve les droits exclusifs de distribution des modèles d’OpenAI, sa décision de ne pas accroître massivement ses engagements en matière d’infrastructures destinées à l’entraînement s’inscrit dans sa stratégie plus large de neutralité vis-à-vis des modèles. Microsoft souhaite qu’Azure soit la plateforme de choix, non seulement pour les modèles d’OpenAI, mais aussi pour tous les modèles que ses clients choisissent pour leurs besoins d’inférence.
Plutôt que d’augmenter agressivement ses dépenses d’investissement en prévision de futures avancées technologiques, Microsoft ajuste ses investissements du côté de l’offre (tels que les clusters de GPU, l’expansion des centres de données et le développement de modèles exclusifs) en fonction de la demande observable des clients et de la valeur réalisée à partir des besoins d’inférence. Concrètement, Microsoft suit de près les tendances d’utilisation, les taux d’adoption par les entreprises et la contribution aux revenus des outils d’IA déjà déployés, et utilise ces indicateurs pour orienter ses futurs investissements en infrastructures. Concrètement, Microsoft suit de près les tendances d’utilisation, les taux d’adoption par les entreprises et la contribution aux revenus des outils d’IA déjà déployés, et utilise ces indicateurs pour orienter ses futurs investissements en infrastructures.
L’avantage technique et financier d’Alphabet
L’approche d’Alphabet en matière d’IA générative s’inscrit dans une philosophie d’innovation continue, exploitant ses compétences en recherche via Google DeepMind, ses infrastructures via le service Google Cloud, et sa capacité de distribution grâce à ses produits et services utilisés par des milliards de clients à travers le monde. Bien que l’entreprise propose des modèles d’IA tiers, elle investit également de manière stratégique dans la construction de son propre écosystème d’IA générative avec sa famille de LLM multimodaux, Gemini.2 Si les trois grands hyperscalers (Amazon, Microsoft et Google) offrent tous des services cloud complets, Google est souvent cité comme disposant de l’infrastructure cloud la plus intégrée verticalement, depuis les câbles sous-marins jusqu’à l’utilisation à grande échelle de circuits intégrés conçus en interne, ce qui lui confère plusieurs avantages stratégiques. Un exemple emblématique en est la conception interne des Tensor Processing Units (TPU), des puces spécifiquement conçues pour les besoins en calcul de l’IA. Déployées pour la première fois dans leurs centres de données en 2015, ces TPU alimentent aujourd’hui l’ensemble des opérations d’entraînement et d’inférence des modèles de pointe Gemini. Grâce à des années d’itérations continues, les TPU ont permis à Google de proposer non seulement certains des meilleurs modèles d’IA du marché, mais aussi avec une efficacité remarquable en termes de coûts. Comme l’illustre le graphique ci-dessous, les modèles de Google se situent sur la « frontière de Pareto » en matière de performance (axe vertical) et de coût (axe horizontal), ce qui en fait une proposition particulièrement attrayante pour les clients. En d’autres termes, toute alternative serait sous-optimale pour l’utilisateur, car un gain dans un domaine (comme le prix) impliquerait nécessairement un compromis dans un autre (comme la performance).
Figure 2 : Performance des grands modèles de langage (LLM) par rapport au coût par calcul
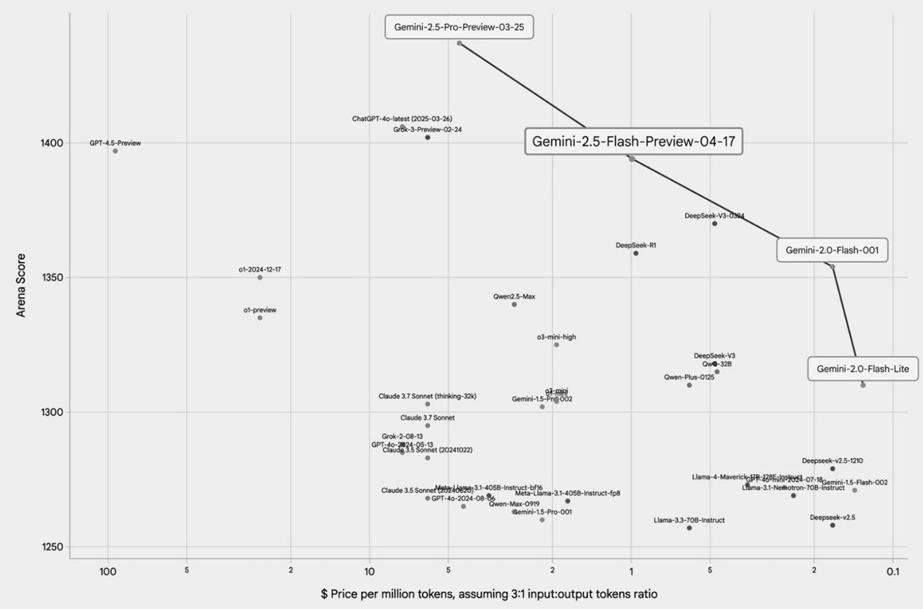
Source : Google for Developers Blog (17 avril 2025)
Ces puces confèrent à Google un avantage structurel en matière de coûts qui s’étend à l’ensemble de ses activités liées à l’IA. Alors que des concurrents comme OpenAI (dépendant de Microsoft Azure) et Anthropic (dépendant d’Amazon Web Services) doivent se procurer une infrastructure cloud tierce onéreuse pour couvrir leurs besoins en calcul — supportant souvent ce que certains qualifient de « taxe Nvidia » sur les GPU haut de gamme — l’infrastructure de Google lui permet d’éviter une part significative de ces coûts externes. La publication, en février, par DeepSeek de ses modèles d’IA open source très compétitifs a mis en lumière les inefficacités de coût vertigineuses de nombreux développeurs de grands modèles de langage (LLM), constituant un véritable électrochoc pour l’ensemble du secteur. Pourtant, pour Google — fort de ses années d’investissement dans des entraînements optimisés en termes de coûts et d’une décennie d’itérations et d’améliorations continues sur ses TPU — l’impact a été remarquablement limité. Dans une interview récente, le PDG d’Alphabet, Sundar Pichai, a indiqué que lorsque Google a comparé ses performances à celles des modèles de DeepSeek, il a constaté que ses propres modèles Gemini étaient tout aussi efficaces, voire supérieurs dans certains cas. Cela témoigne de l’avantage considérable que procure à Google son approche intégrée.
La distribution demeure essentielle
Alors que l’engouement actuel autour de l’IA générative semble irrésistible, il existe toujours le risque que la demande se tarisse plus rapidement que prévu. Si ce scénario paraît aujourd’hui peu probable, Alphabet et Microsoft sont néanmoins particulièrement protégés grâce à leur statut d’hyperscalers du cloud et à leurs capacités de distribution inégalées. Même si l’engouement immédiat pour certaines applications d’IA devait s’estomper, la demande sous-jacente pour la puissance de calcul dans le cloud, le stockage de données et les logiciels d’entreprise essentiels perdurera. À mesure que le paysage de l’IA générative évolue, les véritables gagnants ne seront pas seulement ceux qui construiront les modèles les plus avancés, mais surtout ceux qui sauront les distribuer efficacement à grande échelle.
Considérons le cas d’OpenAI. Bien qu’elle soit largement perçue comme un leader dans l’innovation des modèles d’intelligence artificielle, sa viabilité opérationnelle et commerciale est inextricablement liée à Microsoft. Dans le cadre de leur partenariat, OpenAI s’appuie sur Microsoft Azure pour ses besoins en puissance de calcul,3 l’ensemble de ses charges de travail via API étant exclusivement hébergé sur Azure. Cet accord confère non seulement à Microsoft un accès exclusif à la technologie de pointe d’OpenAI, mais il renforce également la position d’Azure en tant que couche fondamentale dans l’architecture en pleine expansion de l’IA. Ce point met en lumière une contrainte stratégique majeure pour OpenAI, en raison de sa dépendance à l’infrastructure et aux capacités de distribution de Microsoft, ce qui limite son indépendance et accentue ses risques d’exécution. En l’absence de son propre cloud de type hyperscale, OpenAI doit s’en remettre à Microsoft non seulement pour la puissance de calcul brute nécessaire à l’entraînement et à l’inférence, mais aussi, de plus en plus, pour atteindre les clients aux points de contact clés dans l’entreprise. Cette dépendance profonde rend le chemin vers une rentabilité durable nettement plus incertain pour OpenAI.
À l’inverse, la force des hyperscalers comme Alphabet et Microsoft réside dans leur contrôle inégalé de la ressource fondamentale pour l’IA – l’infrastructure de calcul – et leur capacité à l’exploiter avec une efficacité extrême à l’échelle, parallèlement à leurs vastes capacités de distribution. Comme l’a déjà expliqué ma collègue Nina, le cœur de la stratégie de Google est résumé par sa devise de longue date : « concentrez-vous sur l’utilisateur et tout le reste suivra« .4 En intégrant de manière transparente des capacités d’IA avancées dans des produits et services existants auxquels des milliards d’utilisateurs font déjà confiance – tels qu’Android, Gmail, YouTube, Workspace et Search – Google est en mesure de générer un engagement plus important et d’offrir des expériences plus personnalisées. Cette utilisation fréquente, associée à une intégration étroite des produits et à une collecte continue des données, constitue une base solide pour le verrouillage des utilisateurs et, en fin de compte, pour la monétisation.
De même, Microsoft intègre stratégiquement son compagnon numérique doté d’IA, Copilot,5 directement dans ses offres logicielles largement utilisées. Cette approche ajoute des capacités d’IA précisément là où une grande partie du travail de l’entreprise a déjà lieu, éliminant ainsi la nécessité de créer des applications entièrement nouvelles pour que l’utilisation de l’IA puisse se manifester. En intégrant des fonctions d’IA dans Microsoft 365, GitHub et Teams, Microsoft exploite directement une base installée de centaines de millions d’utilisateurs. En retour, cela permet à Microsoft de capturer davantage de valeur en améliorant un écosystème logiciel déjà bien établi.
Dans ce paysage en pleine évolution, les entreprises qui ne disposent pas de ces deux piliers essentiels – une infrastructure de calcul propriétaire et efficiente et des canaux de distribution vastes et profondément intégrés – peuvent produire de brillants modèles d’IA aujourd’hui, mais seront confrontées à des obstacles majeurs pour atteindre les utilisateurs à grande échelle et générer des marges durables sur le long terme. À cet égard, Microsoft et Alphabet sont toutes deux bien placées pour mener la prochaine ère d’innovation et de création de valeur axée sur l’IA.
1Il s’agit là d’un modèle possible (il n’y aura pas toujours une entreprise distincte ou unique pour chaque couche – par exemple, Microsoft fournit à la fois la couche informatique et la couche applicative).
2Les LLM multimodaux peuvent traiter et comprendre des informations issues de plusieurs modalités — texte, image, audio et vidéo — et générer aussi des contenus dans divers formats.
3Un amendement à l’accord, conclu plus tôt cette année, accorde à Microsoft un « droit de premier refus » sur toute nouvelle capacité de cloud computing si OpenAI envisage de faire appel à un fournisseur concurrent.
4https://about.google/company-info/philosophy/
5 Microsoft utilise actuellement les derniers modèles d’OpenAI pour les services Copilot qu’elle propose à ses clients.
Le présent document est une communication marketing / promotion financière destinée à des fins d’information uniquement et ne constitue en aucun cas un conseil en matière d’investissement. Toutes les prévisions, opinions, objectifs, stratégies, perspectives et/ou estimations et attentes ou autres commentaires non historiques contenus dans le présent document ou exprimés dans ce document sont basés sur les prévisions, opinions et/ou estimations et attentes actuelles uniquement, et sont considérés comme des « énoncés prospectifs » . Les énoncés prospectifs sont assujettis à des risques et à des incertitudes qui peuvent faire en sorte que les résultats futurs réels soient différents des attentes.
Il ne s’agit en aucun cas d’une recommandation, d’une offre ou d’une sollicitation d’achat ou de vente d’un produit financier. Le contenu ne prétend pas fournir des conseils comptables, juridiques ou fiscaux et ne doit pas être considéré comme tel. Son contenu, y compris les sources de données externes, est considéré comme fiable, mais ne fait l’objet d’aucune assurance ou garantie. Aucune responsabilité ou obligation ne sera acceptée pour modifier, corriger ou mettre à jour toute information dans le présent document.
Veuillez noter que les performances passées ne doivent pas être considérées comme une indication des performances futures. La valeur de tout investissement et/ou instrument financier inclus dans ce site Web et les revenus qui en découlent peuvent fluctuer et les investisseurs risquez de pas récupérer le montant initialement investi. En outre, les fluctuations des devises peuvent également entraîner une hausse ou une baisse de la valeur des investissements.
Ces informations ne sont pas destinées à être utilisées par des ressortissants des États-Unis. Elles peuvent être utilisées par des succursales ou des agences de banques ou de compagnies d’assurance organisées et/ou réglementées par la législation fédérale ou étatique des États-Unis, agissant pour le compte de particuliers non américains ou distribuant des produits à ces derniers. Il est interdit de diffuser ce document auprès des clients de ces succursales ou agences ou du grand public.
Recevez les dernières informations et événements directement dans votre boîte de réception
« * » indique les champs nécessaires